Ciencia Pokémon: Un proyecto End-to-End de MLOps
Publicado el 20 de agosto de 2025 en Python

¿Qué tienen en común Pokémon y un proyecto de Machine Learning de nivel profesional? Más de lo que te imaginas. Detrás de la nostalgia y las batallas, el universo Pokémon es un ecosistema de datos increíblemente rico, el campo de juego perfecto para construir y demostrar un ciclo de vida completo de MLOps.
En este artículo, te llevaré en un viaje a través de mi proyecto “Ciencia Pokémon”. El objetivo no es la precisión de un modelo, sino implementar una arquitectura robusta, reproducible y automatizada para resolver un problema divertido: predecir el tipo de un Pokémon basándonos únicamente en el color dominante de su sprite. Todo esto, empaquetado y servido a través de una API RESTful lista para producción.
La Chispa: Descubriendo los Secretos de la Pokédex
Todo gran proyecto de datos empieza con una pregunta. La mía era: más allá de lo que nos dicen los juegos, ¿qué patrones ocultos existen en los stats de más de 1000 Pokémon? Antes de escribir una sola línea de código para un modelo, me sumergí en un profundo Análisis Exploratorio de Datos (EDA). Los hallazgos fueron la verdadera chispa que encendió este proyecto.
Arquetipos de Combate Ocultos
Decidí ignorar las etiquetas y dejar que los datos hablaran por sí mismos. Usando un algoritmo de clustering K-Means sobre las estadísticas base (HP, Ataque, Defensa, etc.), los Pokémon se agruparon de forma natural en 5 “roles” o arquetipos de combate distintos. La visualización con PCA fue reveladora: un eje representaba el “Poder General”, mientras que el otro definía un espectro entre “Agilidad vs. Robustez”.
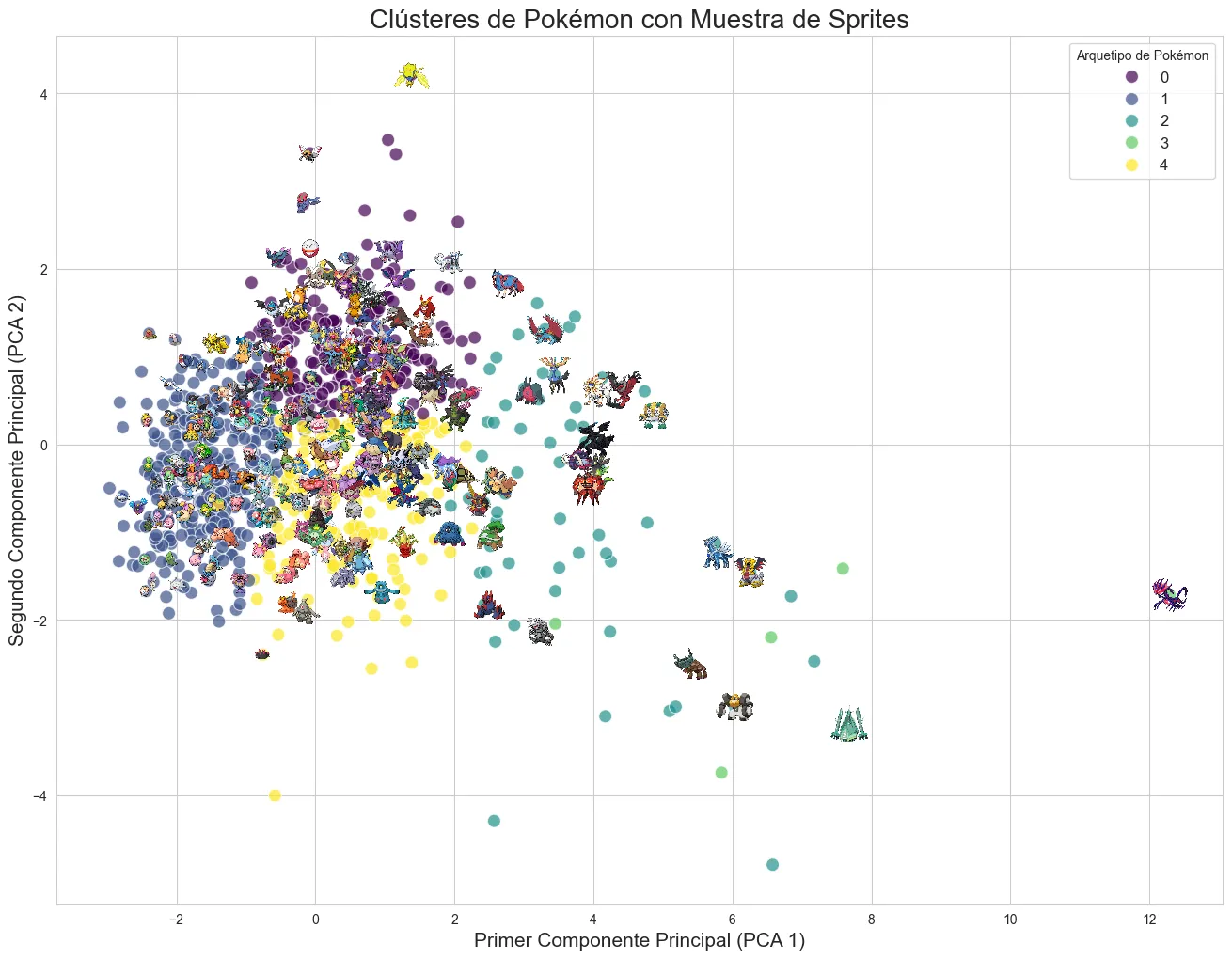
El “Power Creep” es Real
También confirmé una sospecha de muchos fans: el “power creep” existe. Hay una tendencia estadísticamente clara que muestra cómo las estadísticas totales promedio de los Pokémon han ido aumentando en las generaciones más recientes.
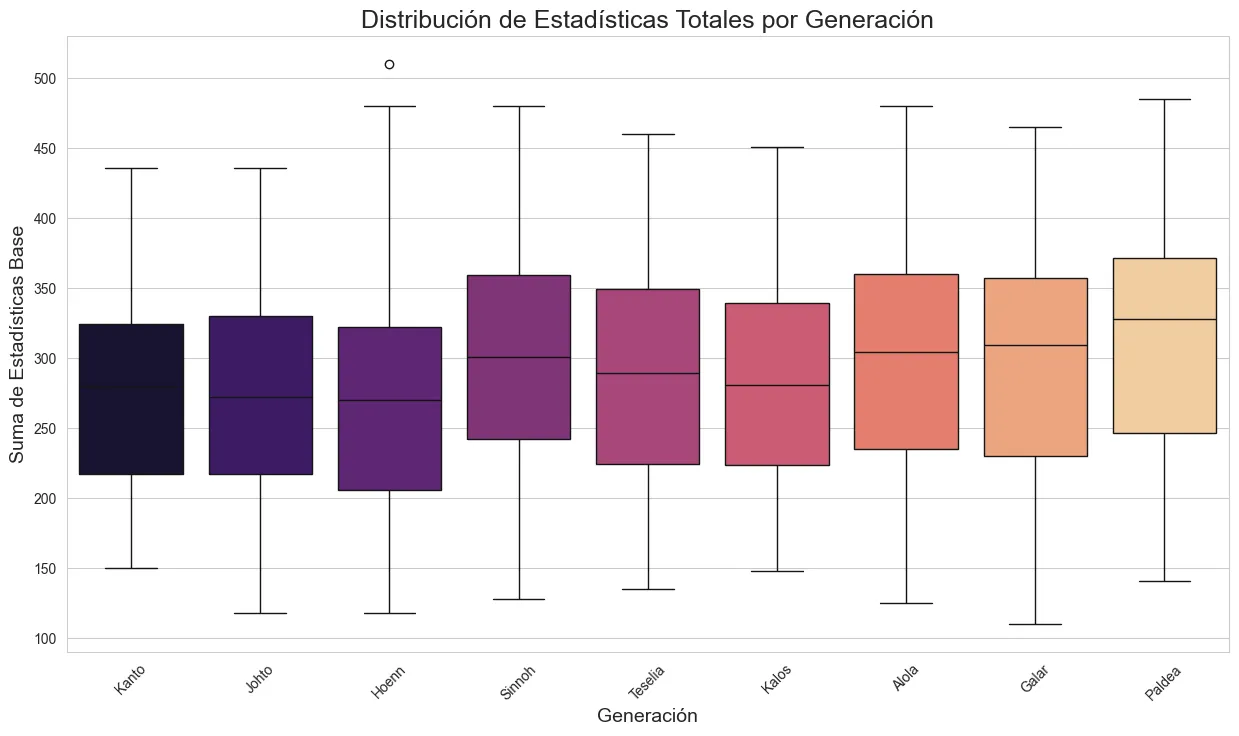
Con estos insights, y viendo que había una estructura coherente en los datos, me sentí con la confianza para abordar el objetivo principal: si el color de un Pokémon está tan ligado a su tipo, ¿podríamos predecirlo?
La Arquitectura: Un Enfoque MLOps Profesional
Un notebook de Jupyter es genial para explorar, pero para crear un producto de software real, se necesita una estructura. Diseñé un flujo de trabajo que asegura la calidad y la reproducibilidad en cada etapa.
-
🧪 Seguimiento con MLflow: Cada experimento, cada ajuste de hiperparámetros, fue registrado meticulosamente con MLflow. Esto me permite tener una trazabilidad completa, comparar resultados y saber exactamente qué versión del modelo es la que mejor funciona, evitando el caos de tener docenas de notebooks llamados
modelo_final_final_v2.ipynb. -
📦 Versionamiento con DVC: Los modelos entrenados y los datasets pueden ser pesados. En lugar de subirlos a Git, usé DVC (Data Version Control) para versionarlos. Esto mantiene el repositorio ligero mientras asegura que cualquiera pueda reproducir mis resultados descargando la versión exacta de los datos y el modelo que usé.
-
🚀 Despliegue con FastAPI y Docker: El modelo final se envolvió en una API RESTful con FastAPI. ¿Por qué? Porque es increíblemente rápido, moderno y genera documentación interactiva de la API de forma automática (¡hola, Swagger UI!). Toda esta aplicación fue encapsulada en un contenedor de Docker, garantizando que funcione de la misma manera en cualquier entorno, desde mi laptop hasta un servidor en la nube.
El código para un endpoint de predicción en FastAPI es un gran ejemplo de simplicidad y poder:
# fragmento de src/api/main.py @app.post("/predict") def predict(pokemon_name: str): """ Predice el tipo de un Pokémon basándose en su nombre. """ try: # Lógica para obtener el sprite, extraer el color y predecir color_hex = get_dominant_color_from_sprite(pokemon_name) prediction = model.predict([color_hex])[0] return {"pokemon": pokemon_name, "predicted_type": prediction} except Exception as e: raise HTTPException(status_code=404, detail=str(e)) -
🤖 Automatización con GitHub Actions: Para cerrar el ciclo, configuré un pipeline de Integración Continua (CI) con GitHub Actions. Cada vez que hago un
push, se ejecutan automáticamente las pruebas unitarias (pytest), asegurando que ningún cambio nuevo rompa la funcionalidad existente.
Conclusión: Más Allá del Modelo
Este proyecto fue un ejercicio práctico para demostrar que los principios de MLOps no están reservados para las grandes empresas. Herramientas de código abierto como MLflow, DVC y Docker son accesibles y transforman un simple script de machine learning en un producto de software robusto, versionado y desplegable.
La historia que nos cuentan los datos de Pokémon es fascinante, revelando una complejidad inesperada. Pero la historia más importante aquí es cómo podemos tomar esa curiosidad inicial, validarla con un análisis de datos sólido y, finalmente, construir sistemas de IA de manera profesional y escalable.
Si te interesa explorar el código, las pruebas automatizadas o incluso ejecutar la API en tu propia máquina, te invito a visitar el repositorio completo en mi perfil de GitHub.
También te podría interesar

PyntegrityDB: Mi Herramienta Open-Source en Python para Garantizar la Calidad de tus Datos
Te presento PyntegrityDB, una biblioteca y CLI que construí para automatizar la validación de integridad en bases de datos PostgreSQL y MySQL. Descubre por qué la creé y cómo puede ayudarte.

Escrito por
Osvaldo Trujillo
Ingeniero de Machine Learning, Arquitecto AWS y desarrollador. Apasionado por la tecnología y la creación de soluciones que aportan valor a través de los datos.
GitHub LinkedIn Contáctame