PyntegrityDB: Mi Herramienta Open-Source en Python para Garantizar la Calidad de tus Datos
Publicado el 17 de agosto de 2025 en Python

En el mundo de los datos, a menudo nos obsesionamos con los modelos de Machine Learning y los dashboards impresionantes. Pero hay un héroe silencioso que sostiene todo ese ecosistema: la integridad de los datos. Si tus datos no son confiables, tus análisis y predicciones tampoco lo serán.
Trabajando en varios proyectos, me encontré repetidamente con el mismo desafío: verificar que los datos en nuestras bases de datos (PostgreSQL, MySQL) cumplieran con las reglas de negocio. ¿Hay valores nulos donde no debería? ¿Existen duplicados en claves primarias? ¿Los tipos de datos son los correctos? Hacer estas validaciones manualmente es tedioso y propenso a errores.
Cansado de escribir scripts repetitivos para cada nuevo proyecto, decidí construir una solución unificada. Así nació PyntegrityDB, mi herramienta de línea de comandos (CLI) de código abierto, desarrollada en Python para automatizar la validación de la integridad de los datos.
¿Qué es PyntegrityDB?
PyntegrityDB es una utilidad que se conecta a tu base de datos y ejecuta una serie de pruebas de validación que defines en un simple archivo de configuración YAML. Su objetivo es simple: darte un reporte claro y rápido sobre la salud de tus tablas, permitiéndote detectar problemas antes de que impacten tus aplicaciones o análisis.
Las validaciones que puedes realizar incluyen:
- Verificar que una columna no contenga valores nulos (
not_null). - Asegurar que todos los valores en una columna sean únicos (
unique). - Confirmar que los valores de una columna se encuentren dentro de un conjunto predefinido (
in_values). - Y muchas más.
¿Cómo Funciona? El Poder de un YAML Simple
En lugar de escribir código complejo, defines tus pruebas en un archivo config.yaml. Esto desacopla las reglas de validación de la lógica de la aplicación, haciendo que sea muy fácil de mantener.
Imagina que quieres validar una tabla de usuarios:
# config.yaml
tables:
users:
columns:
user_id:
not_null: true
unique: true
email:
not_null: true
unique: true
status:
in_values:
- active
- inactive
- pendingLuego, desde tu terminal, simplemente ejecutas la herramienta:
pyntegritydb --config config.yaml --db-uri "postgresql://user:pass@host/db"La herramienta se conecta, ejecuta cada una de las 9 validaciones definidas y te entrega un resumen claro. Si encuentra un error, como un email duplicado, te lo informará al instante.
¿Cómo llevas una herramienta de calidad de datos al límite?
Quise probar la potencia de pyntegritydb, así que simulé un escenario adverso para cualquier equipo de datos:
- Creé una base de datos TPC-H de +1 GB con millones de registros de pedidos, clientes y productos.
- Luego, la corrompí intencionadamente: borré miles de clientes para dejar pedidos huérfanos y actualicé claves foráneas para que apuntaran a la nada.
El resultado: una base de datos masiva con más de 150,000 errores de integridad referencial escondidos.
El momento de la verdad. Ejecuté un solo comando:
pyntegritydb "postgresql:[ruta]" --config config.yml --visualizeEn menos de 60 segundos, la herramienta no solo procesó los millones de registros, sino que:
- ✅ Identificó cada uno de los +150,000 errores de completitud y consistencia.
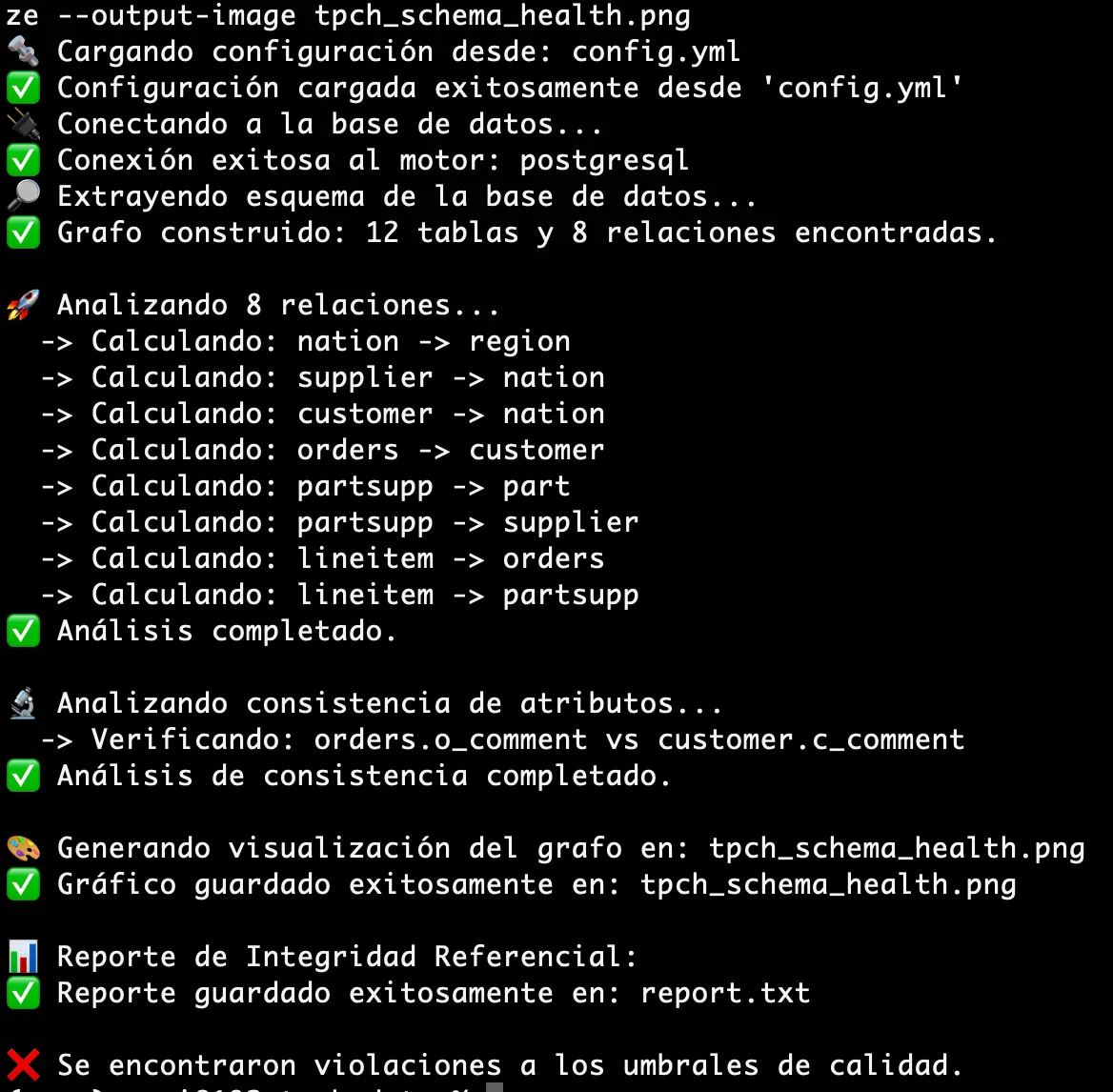
- 🚦 Generó alertas porque los errores violaban los umbrales de calidad que definí.
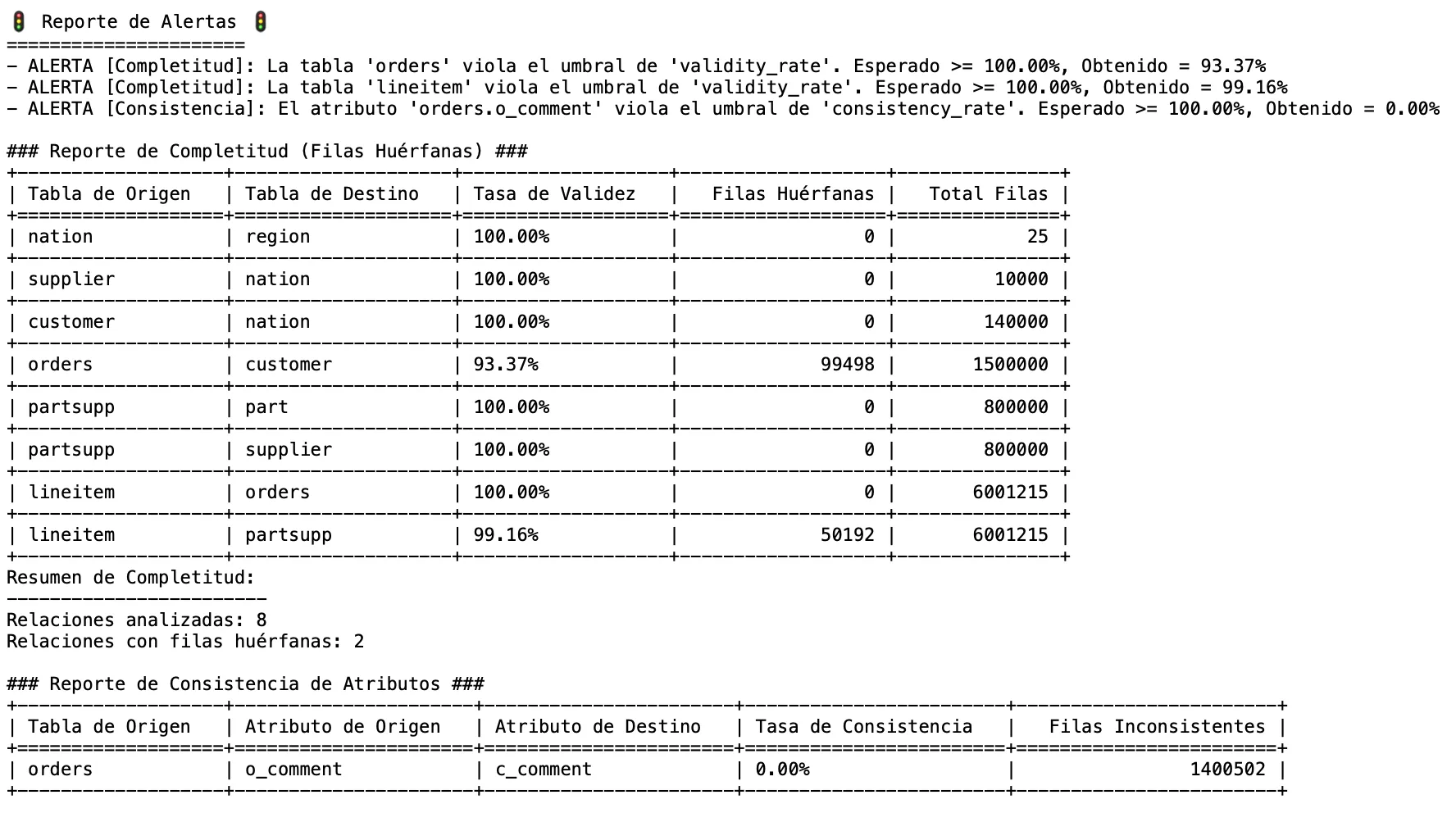
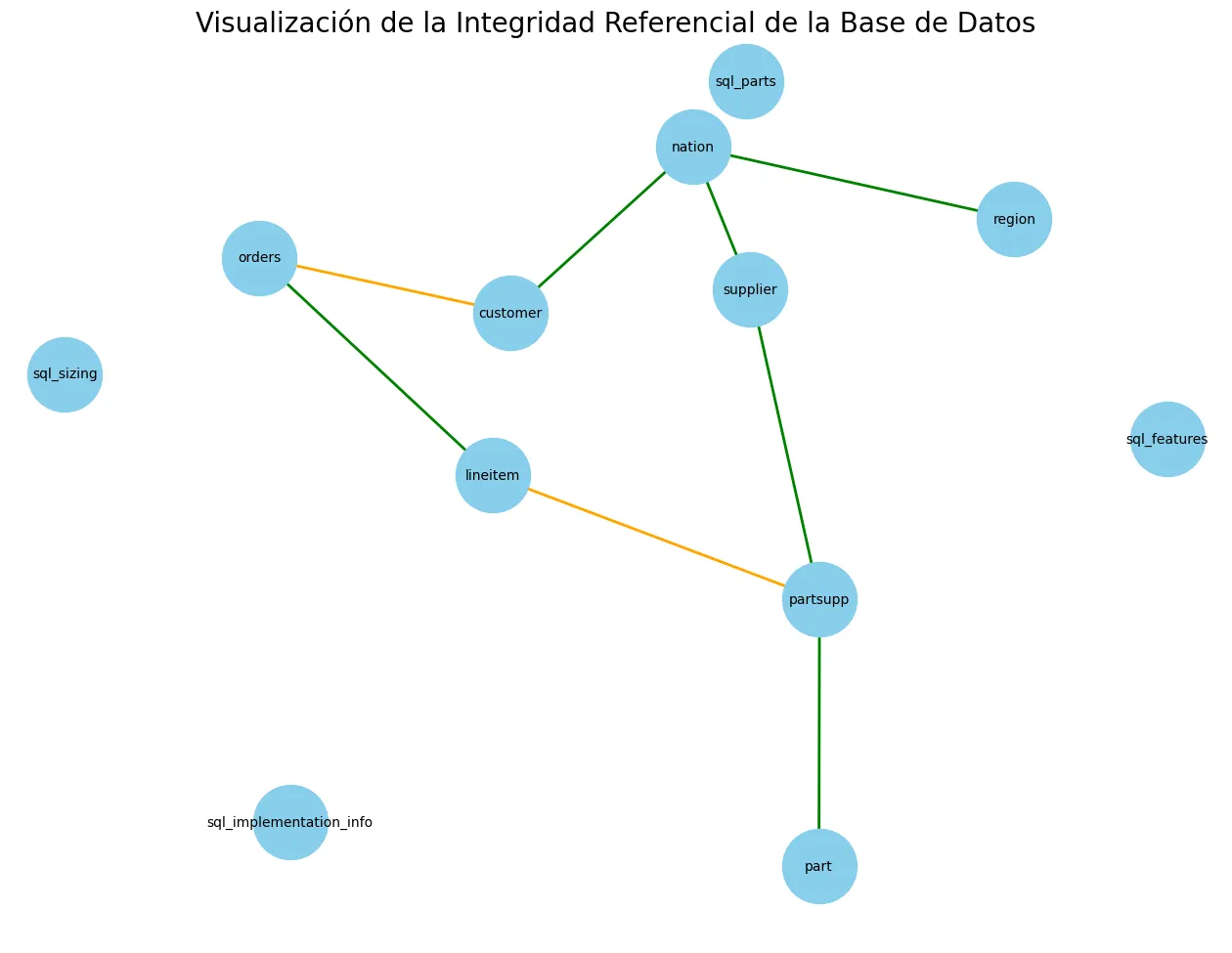
- 🎨 Creó un mapa visual del esquema, destacando en rojo las relaciones rotas.
Esto no se trata solo de encontrar errores; se trata de cuantificar el riesgo en tus datos y obtener una hoja de ruta clara para restaurar la confianza en tus pipelines.
La Historia Detrás de la Herramienta
Como mencioné en una de mis publicaciones en LinkedIn, mi objetivo era tener “confianza total en que nuestros datos cumplen con las reglas de negocio”. PyntegrityDB nació de esa necesidad. Quería una forma de “darle superpoderes a mis validaciones”, permitiéndome ejecutar docenas de pruebas en segundos con un solo comando.
El desarrollo no se detiene. Estoy trabajando en expandir las capacidades de la herramienta, incluyendo la posibilidad de generar automáticamente pruebas de integridad a partir de un schema.yml.
Conclusión
La integridad de los datos no es un tema glamoroso, pero es la base sobre la que se construyen los grandes productos de datos. Construir PyntegrityDB fue mi forma de abordar este desafío de una manera sistemática y reutilizable.
Si trabajas con bases de datos relacionales, te invito a probar la herramienta. Está disponible en PyPI (pip install pyntegritydb) y el código es completamente abierto en GitHub. Todo el feedback, ideas o contribuciones son más que bienvenidos.
También te podría interesar

Ciencia Pokémon: Un proyecto End-to-End de MLOps
Te muestro mi proceso completo de MLOps: desde el análisis de datos hasta el despliegue de una API con Docker y FastAPI para predecir el tipo de un Pokémon por su color.

Escrito por
Osvaldo Trujillo
Ingeniero de Machine Learning, Arquitecto AWS y desarrollador. Apasionado por la tecnología y la creación de soluciones que aportan valor a través de los datos.
GitHub LinkedIn Contáctame