Arquitectura de un pipeline de datos en AWS
Publicado el 10 de septiembre de 2025 en Cloud
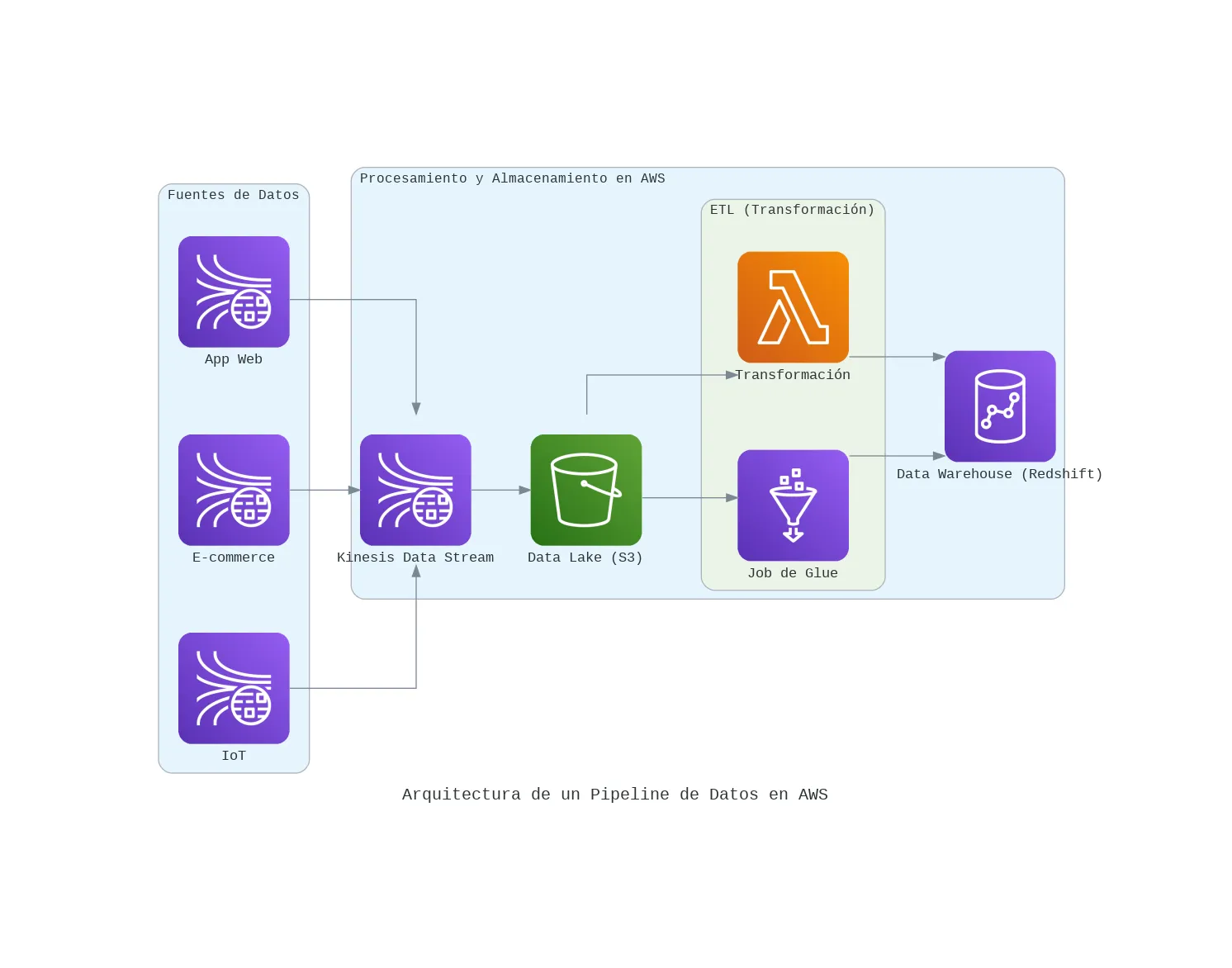
En el mundo actual, los datos son el activo más valioso de una empresa. Pero tener datos no es suficiente; la clave está en la capacidad de recolectarlos, procesarlos y analizarlos de manera eficiente para tomar decisiones de negocio inteligentes. Aquí es donde entra en juego un pipeline de datos bien diseñado.
Como arquitecto, a menudo me enfrento al desafío de construir estos pipelines. La pregunta no es solo “cómo lo hacemos”, sino “¿cuál es la forma más escalable, rentable y mantenible de hacerlo?”. Hoy quiero compartir mi arquitectura en AWS, una plantilla que he refinado a través de varios proyectos para construir sistemas de datos robustos.
El problema: del caos de datos a la claridad
Imagina un escenario común: una empresa tiene datos generándose constantemente desde múltiples fuentes: clics en su aplicación web, transacciones de su e-commerce, eventos de sus dispositivos IoT, etc. Necesitan un sistema centralizado que no solo almacene esta información, sino que la transforme en insights accionables para sus equipos de negocio.
Un enfoque ad-hoc con scripts manuales y bases de datos sobrecargadas rápidamente se vuelve un caos. Necesitamos una autopista de datos, no un camino de terracería.
Mi solución: una arquitectura de pipeline moderna en AWS
Para resolver este problema, mi arquitectura preferida combina varios servicios gestionados de AWS, cada uno especializado en una etapa del proceso. Esto nos permite enfocarnos en la lógica de negocio y no en la gestión de infraestructura.
1. Ingesta en tiempo real con Amazon Kinesis
Kinesis es la puerta de entrada a nuestro pipeline. Es un servicio diseñado para capturar y procesar grandes volúmenes de datos en streaming en tiempo real.
- Por qué Kinesis: Su integración nativa con el ecosistema de AWS y su capacidad para manejar picos de datos masivos lo hacen ideal. Es la solución perfecta para no perder ni un solo evento.
2. Almacenamiento crudo en Amazon S3 (nuestro data lake)
Todos los datos que llegan a través de Kinesis se almacenan primero, en su formato crudo, en un bucket de S3.
- Por qué S3: Es increíblemente barato, duradero y escalable. Tener una copia de los datos sin procesar en nuestro “lago de datos” (Data Lake) es crucial. Nos permite reprocesar la información en el futuro si nuestras reglas de negocio o nuestros modelos cambian, sin tener que volver a capturarla desde la fuente.
3. Transformación serverless con AWS Lambda o AWS Glue
Una vez que los datos están en S3, una función Lambda o un job de AWS Glue se activa automáticamente. Su trabajo es leer los datos crudos, limpiarlos, enriquecerlos y transformarlos a un formato estructurado y optimizado (como Parquet).
- Por qué Lambda/Glue: Usar un enfoque serverless aquí es clave. Pagamos solo por el tiempo de computación que usamos para la transformación, y se escala automáticamente sin que tengamos que gestionar servidores.
4. Carga en el data warehouse con Amazon Redshift
Los datos ya limpios y estructurados se cargan en Amazon Redshift, nuestro Data Warehouse.
- Por qué Redshift: Está optimizado para realizar consultas analíticas complejas sobre grandes volúmenes de datos a una velocidad impresionante. Es aquí donde los analistas de negocio y científicos de datos pueden conectar sus herramientas (como Power BI o Tableau) para explorar los datos y generar reportes.
Conclusión: una base para decisiones inteligentes
Construir un pipeline de datos no tiene por qué ser una tarea titánica. Al apoyarnos en los servicios gestionados de AWS, podemos diseñar sistemas que son a la vez potentes y flexibles.
Esta arquitectura no es solo un diagrama técnico; es una base que habilita a una organización a moverse más rápido, a entender mejor a sus clientes y a tomar decisiones basadas en datos, no en intuición. Es la infraestructura que convierte el potencial de los datos en valor real de negocio.
También te podría interesar
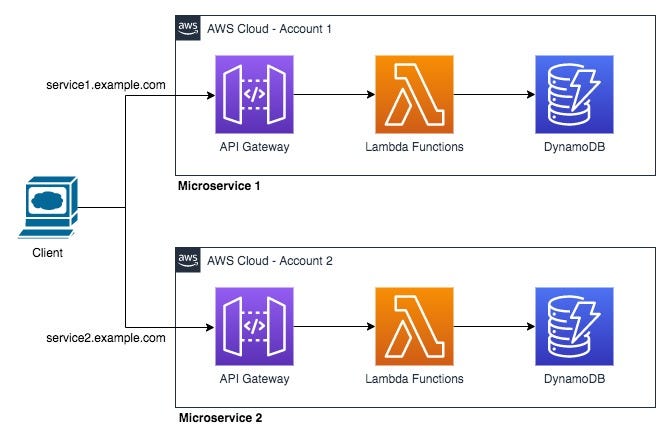
Serverless en AWS: 3 servicios clave que simplifican mi desarrollo backend
La palabra 'serverless' es más que una moda. Te muestro cómo uso el trío de AWS Lambda, API Gateway y DynamoDB para lanzar APIs y microservicios de forma rápida y escalable.
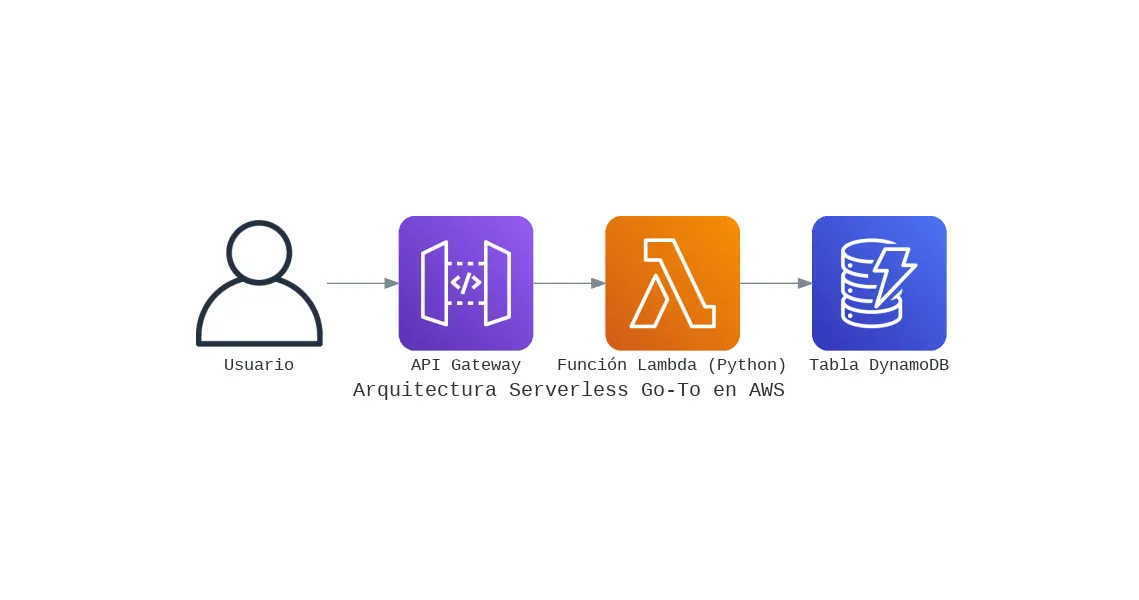
Mi Arquitectura Serverless 'Go-To' en AWS para Proyectos Rápidos y Escalables
Te comparto mi plantilla de arquitectura serverless en AWS que uso para lanzar backends en minutos, no en días. Una combinación de Lambda, API Gateway y DynamoDB para máxima eficiencia.

De la Laptop a la Nube: Integrando Modelos de ML con AWS SageMaker
Tener un modelo de Machine Learning funcional es solo el primer paso. Descubre cómo usar Amazon SageMaker para desplegar, escalar y gestionar tus modelos en un entorno de producción real.

Escrito por
Osvaldo Trujillo
Ingeniero de Machine Learning, Arquitecto AWS y desarrollador. Apasionado por la tecnología y la creación de soluciones que aportan valor a través de los datos.
GitHub LinkedIn Contáctame