Serverless en AWS: 3 servicios clave que simplifican mi desarrollo backend
Publicado el 19 de septiembre de 2022 en Cloud
La palabra “serverless” suena a magia, pero en realidad es una de las formas más prácticas y eficientes de construir aplicaciones hoy en día sin tener que preocuparse por la gestión de la infraestructura subyacente. Como arquitecto, mi objetivo es siempre encontrar la solución más simple y escalable para un problema, y muy a menudo, la respuesta está en el ecosistema serverless de AWS.
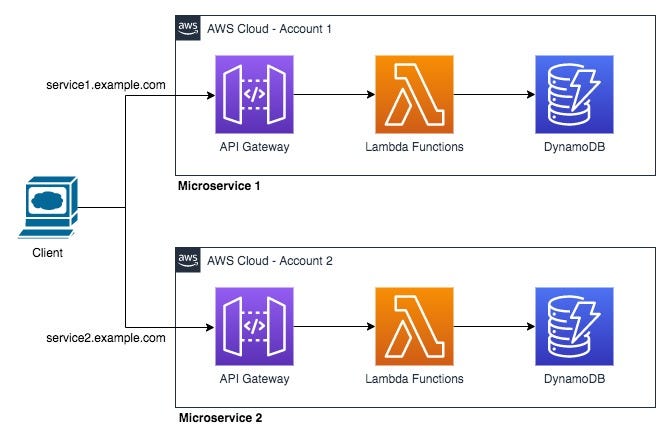
En este artículo, quiero enfocarme en el trío de servicios que se ha convertido en la base de muchos de mis proyectos de backend: AWS Lambda, API Gateway y DynamoDB. Te explicaré qué es cada uno, cómo se conectan y por qué esta combinación es mi favorita para lanzar APIs y microservicios de forma increíblemente rápida.
Los Tres Mosqueteros del Backend Serverless
Pensemos en estos servicios como un equipo especializado donde cada uno tiene una misión muy clara.
1. AWS Lambda: El cerebro
Lambda es el corazón de la operación. Es un servicio de computación que te permite ejecutar código sin aprovisionar o administrar servidores. Simplemente subes tu código (en Python, Node.js, etc.) en forma de “función” y Lambda se encarga de todo lo demás: ejecutarlo, escalarlo y solo cobrarte por el tiempo de computación que consumes, hasta el milisegundo.
- Su trabajo: Contener la lógica de negocio. ¿Necesitas procesar un pago, registrar un usuario o analizar una imagen? Escribes una función Lambda para ello.
2. API Gateway: La puerta de entrada
Tu función Lambda vive aislada en la nube. Para que el mundo exterior (una aplicación web, una app móvil) pueda comunicarse con ella, necesitas una puerta de entrada segura y gestionada. Ese es el trabajo de API Gateway.
- Su trabajo: Crear un endpoint HTTP (una URL) que, cuando se invoca, ejecuta tu función Lambda. Se encarga de la seguridad, el manejo de tráfico (throttling), el cacheo de respuestas y la validación de peticiones. Es el portero robusto de tu backend.
3. DynamoDB: La memoria instantánea
Tus funciones Lambda son “sin estado” (stateless), lo que significa que no recuerdan nada entre ejecuciones. Para guardar información de forma persistente (datos de usuarios, logs, estados de pedidos), necesitas una base de datos. DynamoDB es la base de datos NoSQL nativa de AWS, diseñada para una latencia de milisegundos a cualquier escala.
- Su trabajo: Almacenar y recuperar datos con una velocidad y escalabilidad masivas. Su integración nativa con Lambda es perfecta, permitiendo que tus funciones lean y escriban información de forma casi instantánea.
¿Cómo funciona todo junto? un flujo típico
Imagina que un usuario se registra en tu aplicación:
- El Frontend (tu app web o móvil) envía una petición
POSTa la URL gestionada por API Gateway. - API Gateway recibe la petición, la valida y la reenvía para invocar a tu función Lambda de “registro de usuario”.
- La función Lambda se ejecuta, procesa los datos del usuario (hashea la contraseña, valida el email) y escribe el nuevo registro en una tabla de DynamoDB.
- La función Lambda devuelve una respuesta de éxito a API Gateway, que a su vez la reenvía al frontend.
Todo este proceso ocurre en milisegundos, sin que hayas tenido que configurar un solo servidor, parchear un sistema operativo o preocuparte por si necesitas más capacidad si de repente se registran miles de usuarios.
Conclusión
Construir backends de esta manera no solo es eficiente desde el punto de vista del desarrollo, sino también de los costos. Al pagar solo por lo que usas, es una forma increíblemente económica de empezar un proyecto y tienes la tranquilidad de saber que puede escalar para manejar una demanda masiva sin que tengas que intervenir manualmente.
Si estás pensando en tu próximo proyecto de backend, te recomiendo encarecidamente que explores este trío de servicios. Es probable que descubras, como yo, que es la forma más directa y robusta de llevar tus ideas a producción.
También te podría interesar
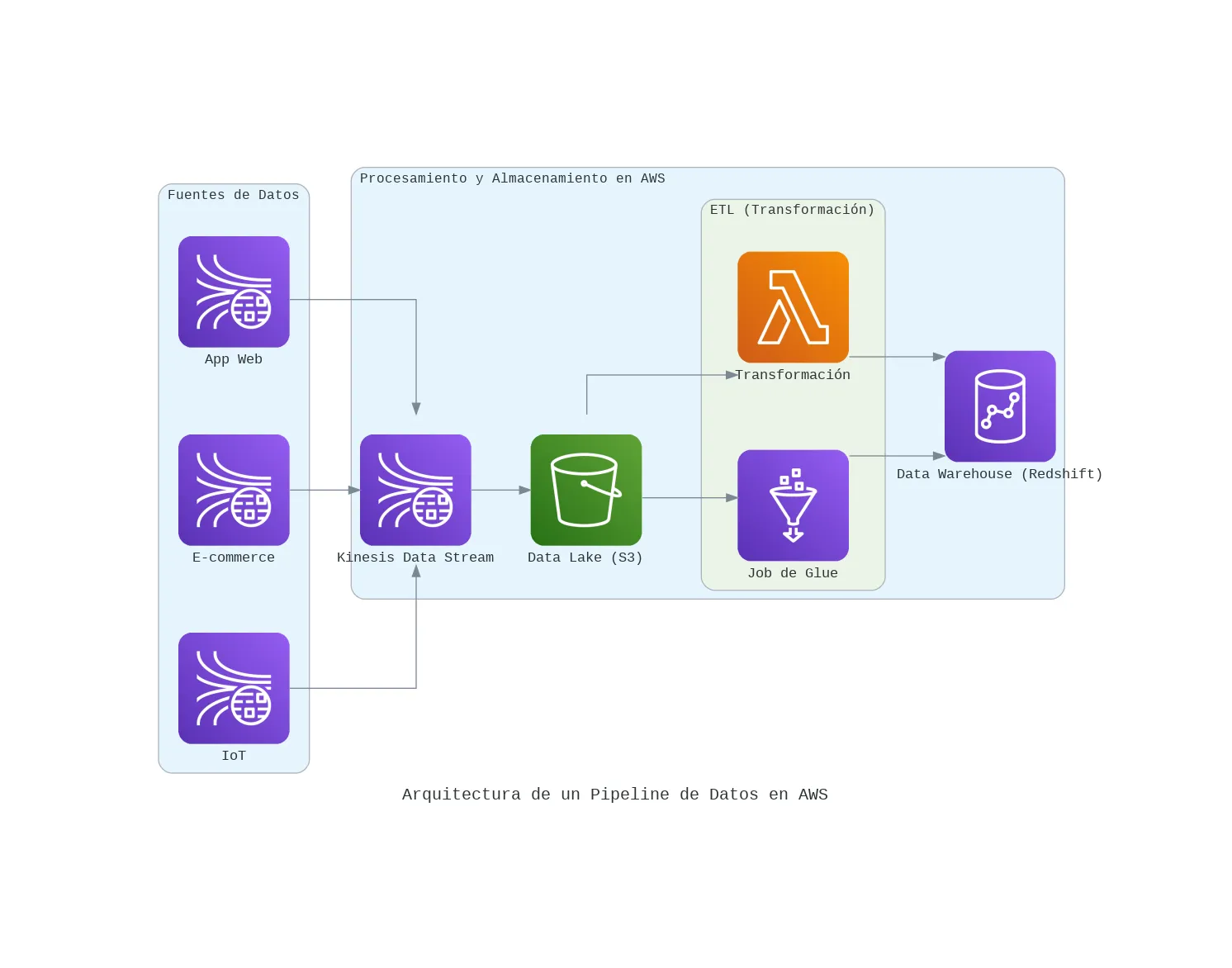
Arquitectura de un pipeline de datos en AWS
Te comparto mi arquitectura para construir un pipeline de datos moderno en AWS, desde la ingesta en tiempo real hasta el análisis. Una guía para tomar mejores decisiones de negocio.
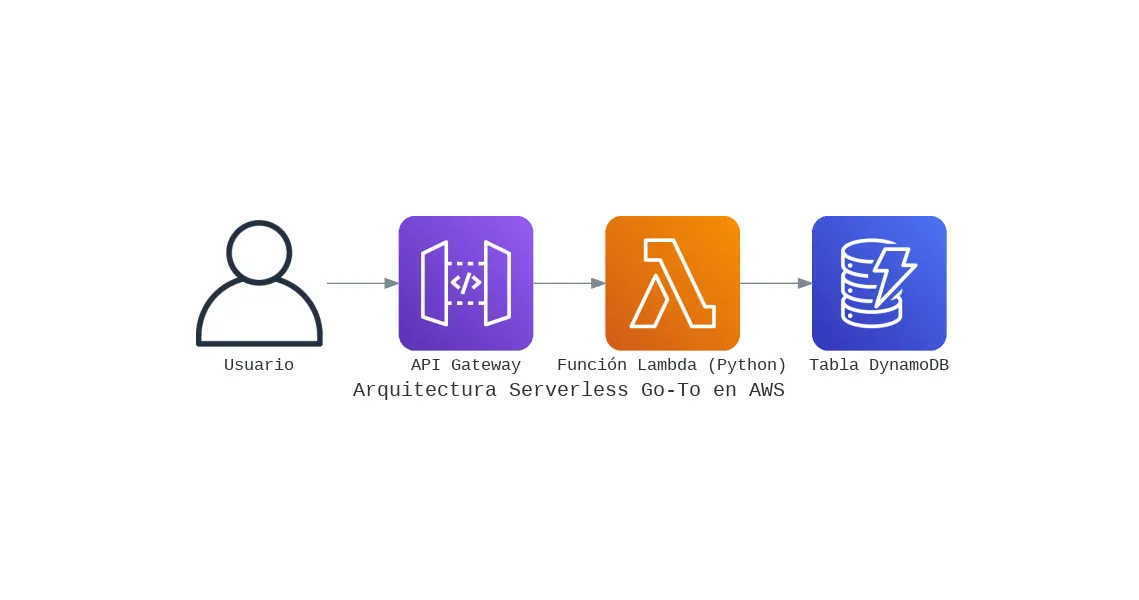
Mi Arquitectura Serverless 'Go-To' en AWS para Proyectos Rápidos y Escalables
Te comparto mi plantilla de arquitectura serverless en AWS que uso para lanzar backends en minutos, no en días. Una combinación de Lambda, API Gateway y DynamoDB para máxima eficiencia.

De la Laptop a la Nube: Integrando Modelos de ML con AWS SageMaker
Tener un modelo de Machine Learning funcional es solo el primer paso. Descubre cómo usar Amazon SageMaker para desplegar, escalar y gestionar tus modelos en un entorno de producción real.

Escrito por
Osvaldo Trujillo
Ingeniero de Machine Learning, Arquitecto AWS y desarrollador. Apasionado por la tecnología y la creación de soluciones que aportan valor a través de los datos.
GitHub LinkedIn Contáctame