De la Laptop a la Nube: Integrando Modelos de ML con AWS SageMaker
Publicado el 15 de septiembre de 2025 en Cloud

El abismo entre el prototipo y la producción
Como arquitecto de IA, he visto un patrón repetirse en muchos equipos: después de semanas de trabajo, el equipo de ciencia de datos presenta un modelo de Machine Learning con resultados impresionantes. Funciona a la perfección en su Jupyter Notebook, predice con una precisión asombrosa y promete revolucionar una parte del negocio. Todos están emocionados.
Pero entonces llega la pregunta clave: “Excelente, ¿cómo lo ponemos en producción?”
Y es ahí donde a menudo aparece un gran abismo. El código que funciona en la laptop de un analista es un mundo aparte de un servicio robusto, escalable y seguro que pueda ser consumido por aplicaciones reales y que soporte miles de peticiones. El camino para cruzar ese abismo se conoce como MLOps (Machine Learning Operations), y es una de las disciplinas más críticas y complejas en el mundo de la IA hoy en día.
Afortunadamente, no tenemos que construir ese puente desde cero. AWS nos ofrece un ecosistema completo diseñado específicamente para cerrar esa brecha: Amazon SageMaker. En este artículo, no vamos a ver a SageMaker como una simple herramienta, sino como la solución estratégica que nos permite llevar nuestros modelos del laboratorio al mundo real.
¿Qué es realmente Amazon SageMaker?
Cuando escuchamos “SageMaker”, es fácil pensar que es una única herramienta o un simple servicio para desplegar modelos. Pero esa visión se queda corta. La mejor forma de entender Amazon SageMaker es verlo como una suite de herramientas integradas que te acompaña durante todo el ciclo de vida del Machine Learning, desde la exploración inicial de los datos hasta el monitoreo del modelo en producción.
Imagina que en lugar de comprar herramientas de diferentes marcas para cada etapa de un proyecto (una para la preparación de datos, otra para el entrenamiento, otra para el despliegue), tuvieras un taller completo y unificado donde cada herramienta está diseñada para funcionar a la perfección con las demás. Eso es SageMaker.
Aunque su ecosistema es muy amplio, incluyendo funcionalidades como SageMaker Studio para la experimentación o SageMaker Training Jobs para entrenamientos a gran escala, en este artículo nos vamos a centrar en el componente que resuelve el problema del “abismo” que mencionamos: el despliegue de modelos como servicios consumibles.
El corazón del despliegue: SageMaker Endpoints
Una vez que tenemos un modelo entrenado, ¿cómo hacemos para que nuestras aplicaciones puedan “hablar” con él? La respuesta en el ecosistema de SageMaker es a través de un Endpoint.
Un endpoint es, en esencia, una API HTTPS segura y totalmente gestionada que “envuelve” a tu modelo de Machine Learning. Su trabajo es recibir datos nuevos (por ejemplo, las características de un nuevo cliente), pasárselos a tu modelo, y devolver la predicción que este genera. Al exponer el modelo a través de una API estándar, cualquier aplicación, sin importar en qué lenguaje esté escrita, puede integrarse con él de forma sencilla y segura.
SageMaker se encarga de toda la complejidad por debajo: provisiona los servidores, instala el software necesario, configura el balanceo de carga para alta disponibilidad y asegura la comunicación. Como arquitectos, nuestro trabajo se centra en elegir el tipo de endpoint adecuado para el problema de negocio que estamos resolviendo. Principalmente, existen tres modalidades:
1. Inferencia en Tiempo Real (Real-Time Inference)
Esta es la opción clásica y la más utilizada. Se provisiona una o más instancias de cómputo que están activas 24/7, listas para recibir peticiones y devolver una predicción en milisegundos.
- Caso de uso ideal: Aplicaciones que necesitan una respuesta instantánea para el usuario final, como sistemas de recomendación de productos, detección de fraude en transacciones o chatbots.
2. Inferencia Serverless (Serverless Inference)
Esta modalidad es perfecta para cargas de trabajo impredecibles o intermitentes. En lugar de tener un servidor siempre encendido, SageMaker provisiona la infraestructura automáticamente cuando llega una petición y la apaga cuando no hay tráfico.
- Caso de uso ideal: Funcionalidades que no se usan constantemente, como el procesamiento de un formulario de contacto con IA o un análisis de imagen que se ejecuta solo unas pocas veces al día. El modelo de costos es de pago por uso, lo que puede ser extremadamente eficiente.
3. Transformación por Lotes (Batch Transform)
No todas las predicciones necesitan ser instantáneas. A veces, lo que necesitamos es procesar un gran volumen de datos de una sola vez. Batch Transform está diseñado para esto. Le das un set de datos completo (por ejemplo, un archivo CSV con miles de clientes) y SageMaker se encarga de obtener las predicciones para cada uno de ellos, guardando los resultados en un bucket de S3.
- Caso de uso ideal: Procesos que se ejecutan de forma periódica, como la segmentación de toda tu base de clientes durante la noche o el análisis de sentimiento de todos los comentarios de un día.
Ejemplo práctico: los pasos para desplegar un modelo
Para hacer esto más tangible, vamos a repasar los pasos conceptuales que seguiríamos para desplegar un modelo de clasificación simple (por ejemplo, uno entrenado con Scikit-learn) y exponerlo a través de un endpoint en tiempo real. No nos sumergiremos en cientos de líneas de código, sino que nos enfocaremos en el “qué” y el “porqué” de cada paso.
Paso 1: Empaquetar y subir el modelo
Lo primero es tomar nuestro modelo ya entrenado, que usualmente es un archivo (como model.joblib o model.pkl), y subirlo a un lugar centralizado y seguro en la nube. El servicio ideal para esto en AWS es Amazon S3 (Simple Storage Service). S3 actúa como nuestro almacén de artefactos, un repositorio donde SageMaker podrá encontrar el modelo cuando lo necesite.
Paso 2: Crear una “definición de modelo” en SageMaker
Una vez que nuestro modelo está en S3, necesitamos decirle a SageMaker cómo usarlo. Esto se hace creando una “Definición de Modelo”. Aquí especificamos dos cosas clave:
- La ubicación del modelo: Le damos la ruta al archivo que subimos a S3.
- El contenedor de inferencia: Le indicamos qué entorno de software necesita el modelo para ejecutarse. SageMaker ofrece contenedores pre-construidos para los frameworks más populares (Scikit-learn, TensorFlow, PyTorch), por lo que en la mayoría de los casos, solo tenemos que elegir el correcto.
Paso 3: Configurar el endpoint
Aquí es donde definimos las características de la infraestructura que servirá nuestro modelo. Creamos una “Configuración de Endpoint” donde especificamos:
- El tipo de instancia: ¿Necesitamos una máquina potente con GPU o una más modesta y económica? La elección depende de la complejidad del modelo y la latencia que necesitemos.
- El número de instancias: Podemos empezar con una sola y configurar el auto-scaling para que SageMaker añada más si el tráfico aumenta.
Paso 4: Crear el endpoint
Con todo lo anterior definido, el último paso es ejecutar el comando para crear el endpoint. En este momento, SageMaker toma el control y automatiza todo el proceso de MLOps: provisiona las instancias, descarga el modelo desde S3, despliega el contenedor, configura la red y expone una URL segura. En cuestión de minutos, lo que eran solo archivos en una laptop se ha convertido en un servicio de inferencia robusto y escalable.
Paso 5: Invocar y obtener predicciones
Una vez que el endpoint está activo, podemos invocarlo desde cualquier aplicación usando el SDK de AWS. El código para hacerlo es sorprendentemente simple. En Python, por ejemplo, se vería algo así:
import boto3
import json
# Cliente de SageMaker
sagemaker_runtime = boto3.client('sagemaker-runtime')
# Datos del nuevo cliente a predecir
datos_nuevos = [[10.2, 5.1, 2.3, 1.4]]
# Nombre de nuestro endpoint
endpoint_name = 'mi-endpoint-de-clasificacion'
# Invocamos el endpoint
response = sagemaker_runtime.invoke_endpoint(
EndpointName=endpoint_name,
ContentType='application/json',
Body=json.dumps(datos_nuevos)
)
# Leemos la predicción
resultado = json.loads(response['Body'].read().decode())
print(f"La predicción del modelo es: {resultado}")Y así, hemos cruzado el abismo. Hemos transformado un modelo estático en un servicio dinámico y productivo.
Conclusión: El valor de negocio no está en el modelo, sino en su despliegue
Tener un modelo de Machine Learning con una alta precisión es un logro técnico impresionante, pero en el contexto de negocio, un modelo que no está en producción tiene un valor real de cero. Su potencial solo se materializa cuando empieza a recibir datos del mundo real y a devolver predicciones que impactan en las operaciones de la empresa.
Herramientas como Amazon SageMaker son una decisión estratégica porque abstraen la complejidad inmensa del MLOps (Machine Learning Operations). Liberan a los equipos de ciencia de datos y de ingeniería de la pesada carga de gestionar infraestructura, configurar redes, balancear cargas y monitorear servidores.
Al adoptar una plataforma gestionada, permitimos que nuestros equipos más talentosos se enfoquen en lo que realmente aporta valor: experimentar, mejorar los modelos y resolver problemas de negocio. La verdadera ventaja competitiva no viene de construir la infraestructura más compleja, sino de la velocidad con la que podemos poner la inteligencia artificial en manos de quienes la necesitan.
En resumen, SageMaker nos permite cruzar el abismo entre el prototipo y la producción de una forma rápida, escalable y segura, transformando nuestros modelos de un ejercicio académico a un activo estratégico para el negocio.
También te podría interesar
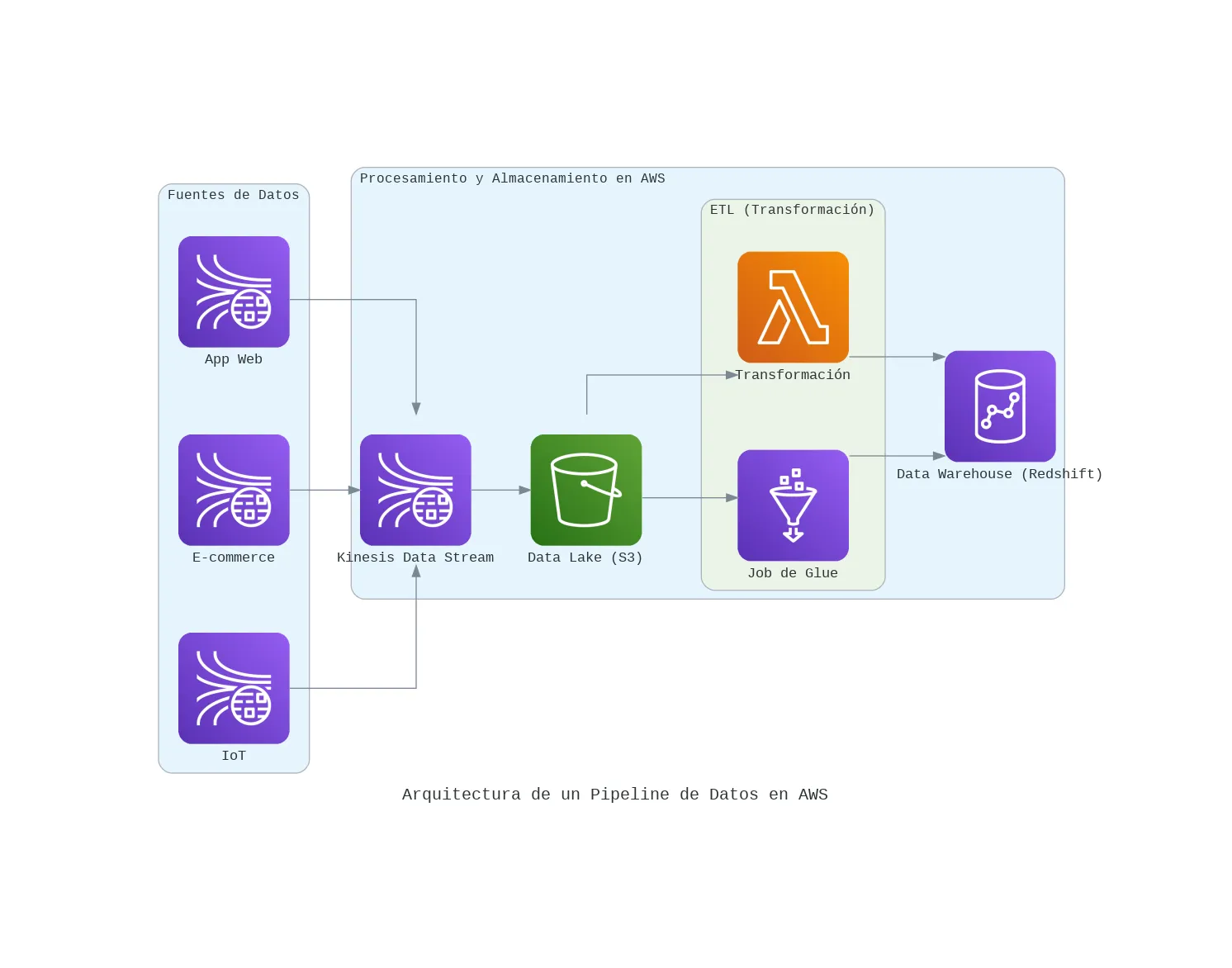
Arquitectura de un pipeline de datos en AWS
Te comparto mi arquitectura para construir un pipeline de datos moderno en AWS, desde la ingesta en tiempo real hasta el análisis. Una guía para tomar mejores decisiones de negocio.
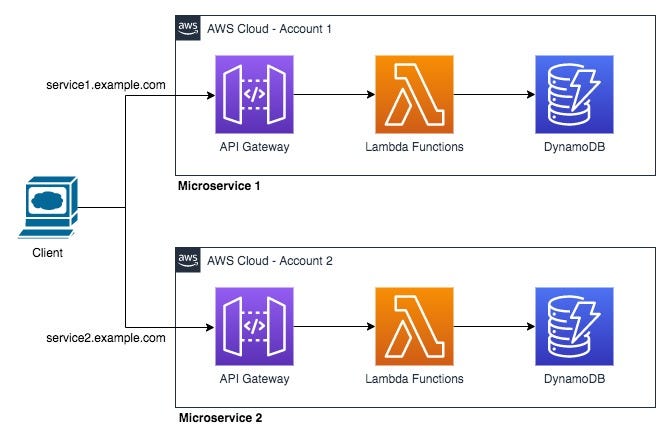
Serverless en AWS: 3 servicios clave que simplifican mi desarrollo backend
La palabra 'serverless' es más que una moda. Te muestro cómo uso el trío de AWS Lambda, API Gateway y DynamoDB para lanzar APIs y microservicios de forma rápida y escalable.
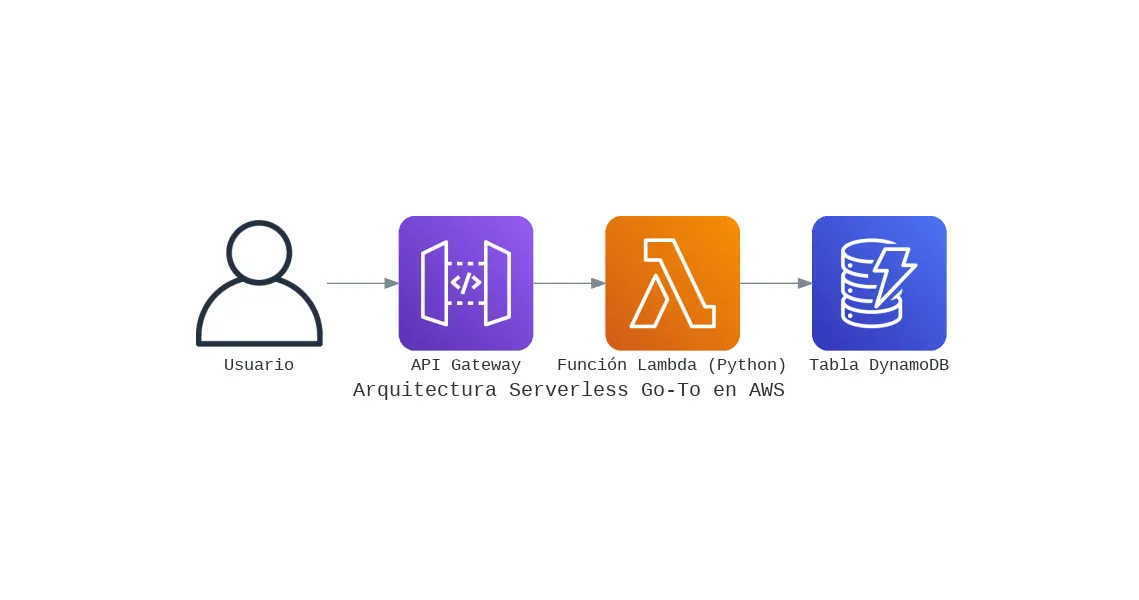
Mi Arquitectura Serverless 'Go-To' en AWS para Proyectos Rápidos y Escalables
Te comparto mi plantilla de arquitectura serverless en AWS que uso para lanzar backends en minutos, no en días. Una combinación de Lambda, API Gateway y DynamoDB para máxima eficiencia.

Escrito por
Osvaldo Trujillo
Ingeniero de Machine Learning, Arquitecto AWS y desarrollador. Apasionado por la tecnología y la creación de soluciones que aportan valor a través de los datos.
GitHub LinkedIn Contáctame